IBM Power10 Coming To Market: E1080 for ‘Frictionless Hybrid Cloud Experiences’
by Dr. Ian Cutress on September 8, 2021 12:01 AM EST- Posted in
- CPUs
- Enterprise
- server
- Enterprise CPUs
- IBM
- POWER10
- E1080
- Hybrid Cloud

Last year IBM presented details about its new Power10 family of processors: eight threads per core, 15 cores per chip, and two chips per socket, with a new core microarchitecture, all built on Samsung’s 7nm process with EUV. New technologies such as PCIe 5.0 for add-in cards, PowerAXON for chip-to-chip interconnect, and OpenCAPI for super-wide memory support made Power10 sound like a beast, but the question was always about time to market – when could customers get one? Today IBM’s Power10 E1080 Servers are being announced, aimed squarely at the cloud market.
Power10: A Brief Summary
IBM’s Power series of processors have been a steadfast progression over the last couple of decades, often using some secret manufacturing process to eke out that specialist frequency right on the bleeding edge. The new Power10 processor is also built for performance, with the 602mm2 16 core silicon die running at over 4 GHz with 8 threads per core. For yield reasons one core per chip is disabled, but a full 16 socket system can run to 1920 logical threads.

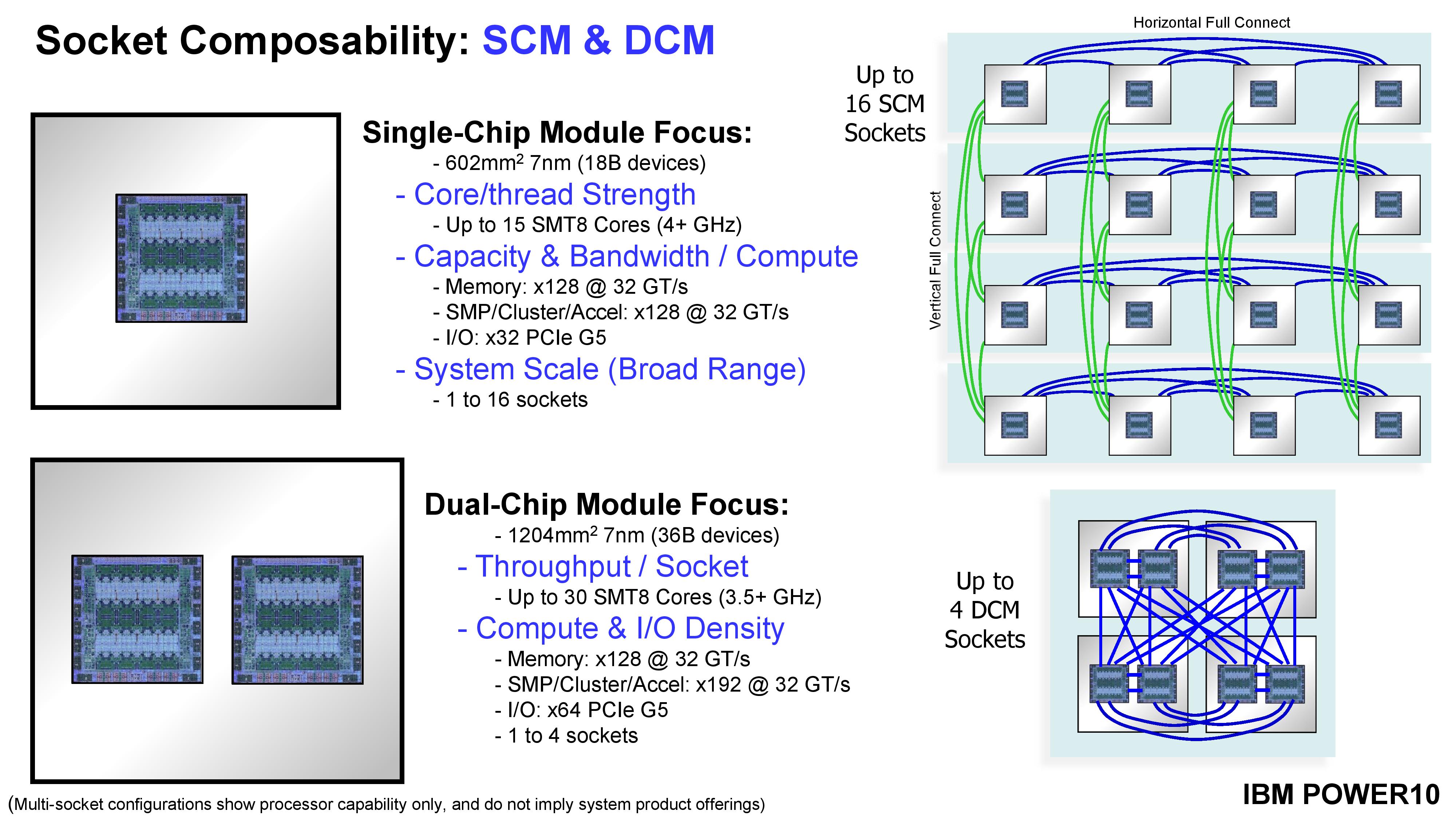
IBM built Power10 to be either in a single chip module (SCM) with one piece of silicon, or a dual-chip module (DCM) with two pieces of silicon. Where the chip really shines is in the two multi-protocol connectivity interfaces around the edges of the silicon.
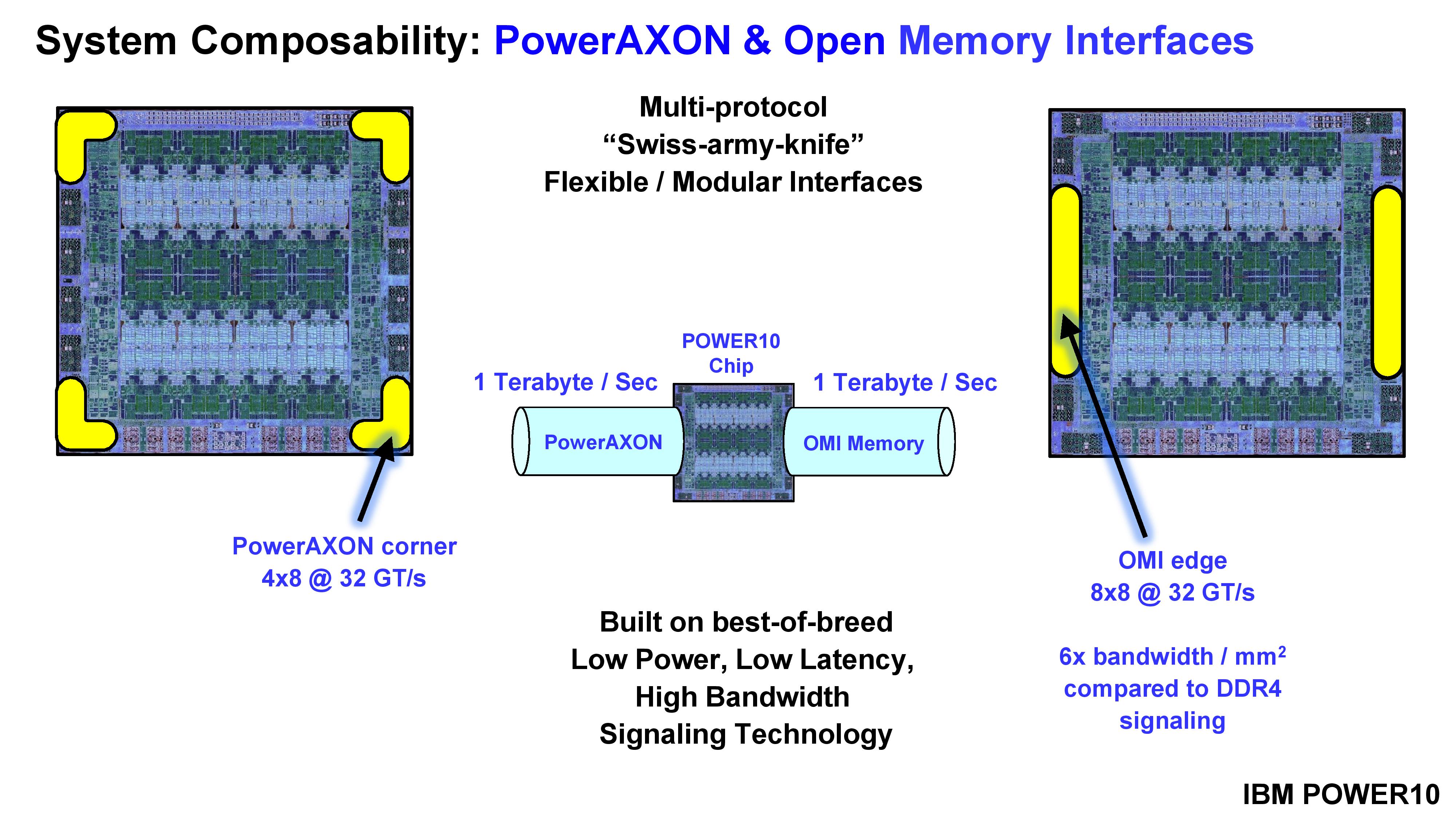
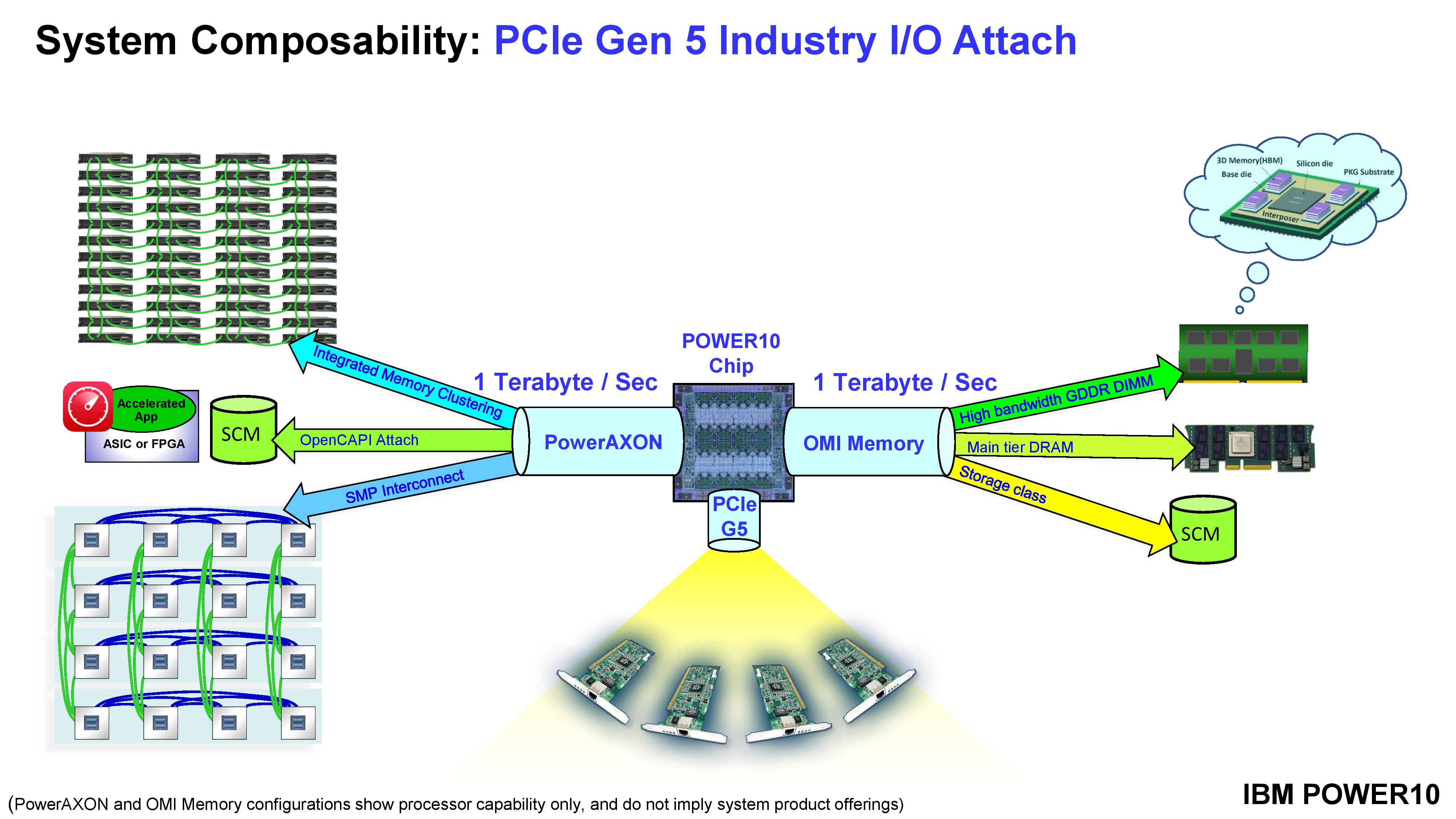
PowerAXON at the corners and OMI (OpenCAPI Memory Interface) sound like amazing flexible interfaces. Running at 1 TB/sec each, the PowerAXON can be used for chip-to-chip communication, storage, regular DRAM, ASICs/FPGA connections, and clustered memory. The OMI can be used for storage also, or main DRAM, or for high-bandwidth GDDR/HBM. Together, these technologies allow for up to 8 TB per system, or 2048 TB of addressable memory across a networked cluster of systems. There’s also PCIe 5.0 x32 for add-in cards.
IBM compares Power10 against Power9: +20% single thread improvement, +30% per core improvement, and an overall 3x performance per watt against the previous 14nm processor. Also bundled is a new AI compute layer supporting four 512-bit matrix engines and eight 128-bit SIMD engines per core, providing 20x or more INT8 performance per socket.

For more slides and details, check our Live Blog from last year’s Hot Chips.
IBM Power10 E1080
The stated E1080 design is an eight-socket system, supporting transparent memory encryption, 2.5x faster encryption, and new RAS features for advanced recovery, self-healing, and diagnostics. IBM’s materials focus on one particular benchmark: how it beats other options in a two-tier SAP Hana SD standard benchmark with only half the sockets, or an Oracle benchmark requiring only 20% of the power and number of Oracle licenses to achieve the same result.

Multiple times in the release IBM mentions ‘instant scaling, pay per use consumption’, especially as it pertains to Red Hat’s OpenShift technology in the cloud. This all pertains to IBM’s ‘Hybrid Cloud’ strategy, which is meant to mean that a business runs some private internal cloud resources while also using some cloud server provider ‘public’ resources, and it’s the public element that relates down to the cost. IBM runs its own cloud service, to which Power10 will be a part.

IBM was relatively light on details about exact SKUs to be offered, memory options, whether these will be available for direct purchase and deployment. A lot of discussions went into the new AI accelerators with ONNX frameworks as well as the operating system support for enterprise features such as side-channel attacks, intrusion detection, compliance reporting, and full-stack encryption with support for ‘quantum-safe cryptography’.
IBM is taking orders now with shipments expected to begin before the end of the month.








24 Comments
View All Comments
eastcoast_pete - Wednesday, September 8, 2021 - link
You had me at "120 Threads per chip". So, how does that compare in compute capabilities with a 64 core/128 thread EPYC, or a similar thread/core count ARM-based server chip? The slides (from IBM) compare this newest Power chip to the predecessor (Power 9), but that doesn't put their newest one into perspective.Wereweeb - Wednesday, September 8, 2021 - link
Anandtech has an article analyzing the Power8 architecture that goes deeper into it: https://www.anandtech.com/show/10435/assessing-ibm...The article is "old" and some things might have changed a bit, but I assume the part about SMT still applies, and you can get the gist of it from this part:
"So we suspect that SMT-8 is only good for very low IPC, "throughput is everything" server applications. In most applications, SMT-8 might increase the latency of individual threads, while offering only a small increase in throughput performance. But the flexibility is enormous: the POWER8 can work with two heavy threads but can also transform itself into a lightweight thread machine gun."
brucethemoose - Wednesday, September 8, 2021 - link
That's how Marvell pitched their SMT8 ARM CPUs IIRC. They were supposedly fantastic in workloads where cores are frequently sitting around, twiddling their thumbs waiting for something from RAM, but could then switch gears if needed.Marvel discontinued that line though...
I can't help but wonder if an asymmetric core architecture would be a better way to achieve that flexibility? It seems like modern big cores waste so much die area for relatively small gains.
RedGreenBlue - Wednesday, September 8, 2021 - link
Workload comparisons could be all over the map because POWER chips are pretty niche products. They’re used for pretty specific workloads. It might be difficult to find proper comparisons because of the RISC architecture they use. Would still be an interesting article though. Long gone are the days of Itanium chips, except... I’m sure there are still some in use. IBM kind of stands alone now in the segment.thunng8 - Wednesday, September 8, 2021 - link
No they are not niche. It will perform well in pretty much any workload you throw at it. It is approx 2.5x faster per core in the industry standard specint 2017 compared to the high end intel Xeon processor120 Power10 core scores 2170
https://spec.org/cpu2017/results/res2021q3/cpu2017...
Compared to 224 core Xeon cores scores 1620
https://www.spec.org/cpu2017/results/res2021q1/cpu...
name99 - Wednesday, September 8, 2021 - link
These are THROUGHPUT machines not latency machines.That's great if what you need is throughput, but the single-threaded performance is mostly not exciting.
Your SPEC results are RATE results not SPECSpeed results. They do not show anything about how this machine would perform for latency tasks (answer, not great -- but that's not its target).
https://www.spec.org/cpu2017/Docs/overview.html#Q1...
kgardas - Wednesday, September 8, 2021 - link
Speaking about power cores does not make a sense when P10 does have 8 threads per core while intel does have just 2. Your referenced machines do have 960 and 448 threads. IBM mines from it 1700 and intel/hp just 1570. So not that big difference. What is important to consider here, that intel is old, very old cooper lake and this core is already updated by ice lake (+19% IPC) and sapphire rapids (+15-20%). As Sapphire Rapids will be '22 material I guess IBM does have around half to whole year for dominating market. Then it will probably be weaker again...(well speaking about cpu throughput -- the machine/cpu/ram hierarchy etc. is engineering marvel of course no doubt about it...)thunng8 - Wednesday, September 8, 2021 - link
Ice lake does not improve the per core throughput.https://spec.org/cpu2017/results/res2021q3/cpu2017...
I have my doubts about Sapphire rapids too.
It is not just spec. new records for sap sd (2.7x per core than ice lake) red hat openshift (4.1x throughput per core) and others been announced.
Single thread performance isn’t too bad either. According to Rperf (power9) from IBM going from single thread to 8 threads get you 2.95x the throughput. If that factor is approx the same for power10, Single thread speed should be approx same as Xeon
name99 - Wednesday, September 8, 2021 - link
You are telling a guy designing a truck that he has lousy acceleration.It may be true, but mainly shows that you don't know what's important in trucks, that you think a truck should be a big sports car.
IBM systems (Power and even more so Z) are primarily about MEMORY, IO, and RAS. They start with astonishingly performant (and expensive!) memory and IO systems, and basically fill in enough compute to fully exploit that memory and IO for the target jobs.
Comparing their compute to Intel or AMD or Apple compute is to miss the point -- instead compare their respective memory and IO systems. And if you don't especially have a desire for such a memory/IO system, if you have "normal" code for which caches work well; yay, congratulations, you are not in the target market.
FreckledTrout - Monday, September 13, 2021 - link
That was very on point.