Interview with Intel’s Raja Koduri: Zettascale or ZettaFLOP? Metaverse what?
by Dr. Ian Cutress on March 9, 2022 12:30 PM EST- Posted in
- CPUs
- Intel
- GPUs
- Zettascale
- Metaverse

We currently live in a sea of buzzwords. Whether that’s something to catch the eye when scrolling through our news feed, or a company wanting to latch their product onto the word-of-the-day, the quintessential buzzword gets lodged in your brain and it’s hard to get out. Two that have broken through the barn doors in the technology community lately have been ‘Zettascale’, and ‘Metaverse’. Cue a collective groan while we wait for them to stop being buzzwords and into something tangible. That long-term quest starts today, as we interview Raja Koduri, Intel’s SVP and GM of Accelerated Computing.
What makes buzzwords like Zettascale and Metaverse so egregious right now is that they’re referring to one of our potential futures. To break it down: Zettascale is talking about creating 1000x the current level of compute today in or around the latter half of the decade, to take advantage of the high demand for computational resources by both consumers and businesses, and especially machine learning; Metaverse is something about more immersive experiences, and 'leveling up' the future of interaction, but is about as well defined as a PHP variable.
The main element that combines the two is computer hardware, coupled by computer software. That’s why I reached out to Intel to ask for an interview with Raja Koduri, SVP and GM, whose role is to manage both angles for the company towards a Zettascale future and a Metaverse experience. One of the goals of this interview was to cut through the miasma of marketing fluff and understand exactly what Intel means with these two phrases, and if they’re relevant enough to the company to be built into those future roadmaps (to no-one’s surprise, they are – but we’re finding out how).
Raja Koduri Intel |
 Ian Cutress AnandTech |
This interview took place before Intel's Investor Meeting
IC: Currently you are the head of AXG, which you started in mid-2021. Previously it was the GM of Architecture, Graphics, and Software group. So what exactly is in your wheelhouse these days? I get the desktop and enterprise graphics, OneAPI too, but what other accelerators?
RK: Good question. So all of our inner Xeon and HPC lines are in the Accelerated Computing graphics. We divide and conquer - we saw that this notion of accelerated computing, which is CPU platforms, GPU platforms, and other accelerators, is very important. For example, recently you heard some news around [Intel’s investments in] blockchain, and there are other interesting things we're working on too. So all of those are in accelerated computing.
IC: Normally when I hear accelerators, I think FPGAs, but that's under Intel’s Programmable Solutions Group, and then there’s networking silicon which is under its own network group. How much synergy is there between you and them?
RK: You know quite a bit, and particularly software and interconnects and fabrics and all. That's a good question by the way. The simple way I define what is accelerated computing is if you're talking around 100 TOPs or more – that’s High-Performance Accelerated Computing. Maybe we didn't want the AXG acronym to be too large, right? So it's shortened - but really, all the high-performance stuff is in AXG.
IC: Initially reached out for this interview because Intel started talking about Zettascale at Supercomputing in November. Then in December, you started also talking about Metaverse. I want to go into those topics, but I would be lynched if I didn't ask you a question about GPUs.
IC: So which of your children do you love more? Alchemist or Ponte Vecchio?
RK: Oh, yeah, you know, both! You can't ask me to choose, at least in an interview, I will get in trouble!
IC: Realistically, internally, you're working on the next generation of graphics, the one after that, and probably the one after that. As GM, I can imagine that on any given day, you're in meetings about Gen1 Gen2, and then a meeting about Gen4, and then another meeting about Gen3. Have you ever turned around and said ‘this week, I'm only focusing say Gen3’, or something similar? How much headspace does that upcoming product, versus future product, have to occupy? I ask this given today, you're talking to me, the press, and I'm going to ask about Gen1.
RK: There are weeks, particularly when I call it a kind of ‘in the creation mode’ when we really finalize the architecture and the core bets we are going to make on which technology. [In those circumstances] that's the only thing I do that entire week, or entire day. I'm personally not that good at mentally context switching and being very productive. So in the next couple of months, as an example, we'll be very much trying to get the Gen1 out into the market. That’s what's right in front of our noses to get all of that stuff done. But yeah, good question!
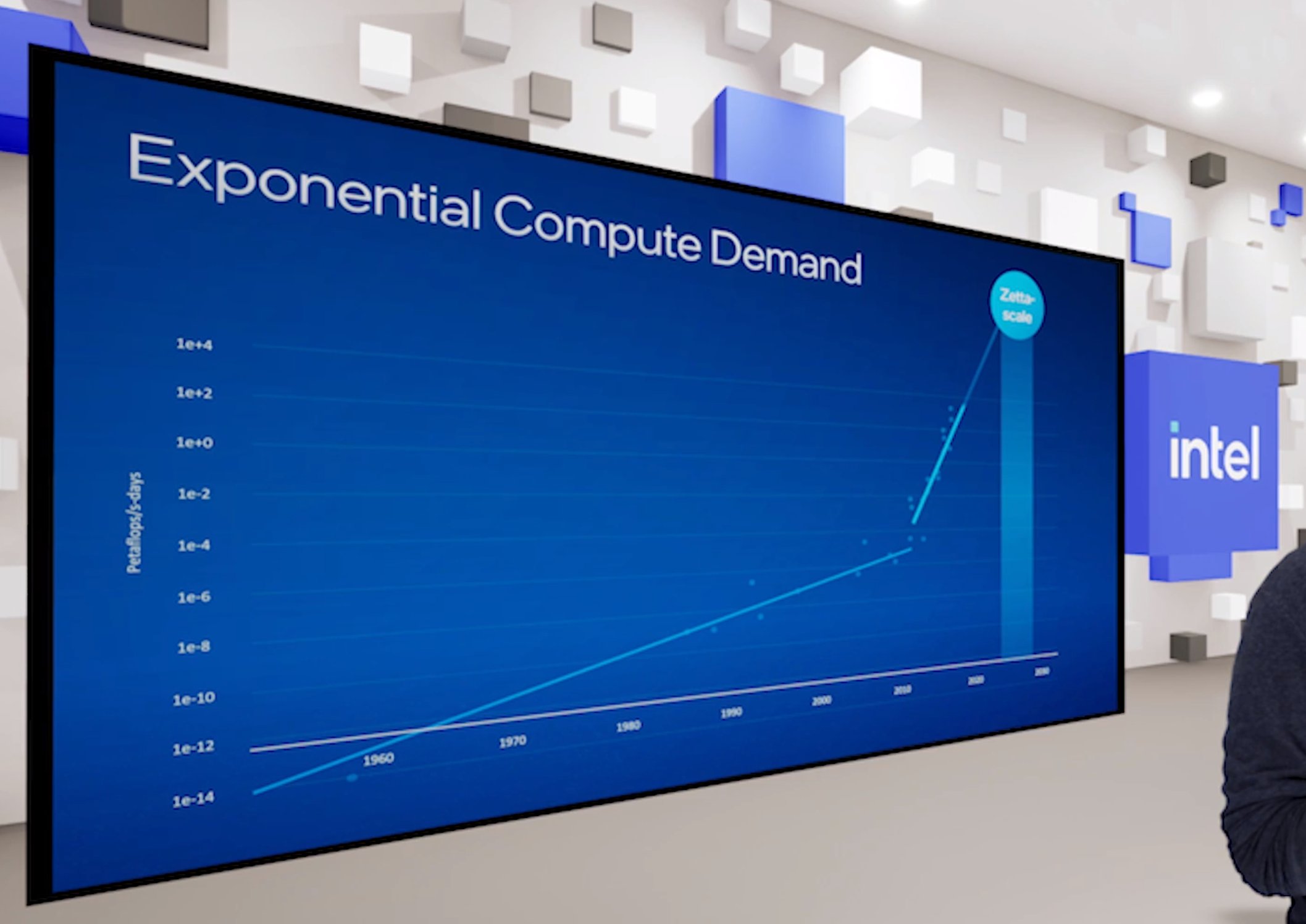
IC: So pivoting to zettascale. Intel made waves in October by announcing a ‘Zettascale Initiative’, right on the eve of the industry breaching that Exascale barrier. Zettascale is a 1000x increase in performance, and Intel claimed a 2027-ish timeframe. In this context, when I say Exascale, I mean one supercomputer, implementing one ExaFLOP of double-precision compute, all 64-bit math. Intel has gone on the record saying that Aurora, the upcoming supercomputer for Argonne, will be in excess of two ExaFLOPs of 64-bit double-precision compute. What I want to ask you is a really specific question about what Intel means by zettascale in this context.
When we say Exascale, we're talking about one machine, one ExaFLOP, double precision.
So by zettascale, do you mean one machine, One zettaFLOP, double-precision, 64-bit compute?
RK: Short answer, yes.
IC: That’s good.
RK: I also want to frame it. If you recall, I have been talking about the need for 1000x more compute, or 1000x performance per watt improvement for a little while. In fact, I think I talked about it in my Hot Chips 2021 keynote, and at a few other events as well. The reason is that the demand for that computer already exists today.
Just taking a concrete example of if I want to train one of the interesting neural nets in real-time. Not training it in minutes, hours or days, but in real-time. The need for that is there today, and the demand for it is there today. So in many ways, we got to figure it out as a technology industry.
That's the fun of being here – figuring out how do we get there? So the fact we say zettacale is kind of a nice numerical way to say it, because we've been talking about 10^18 with Exascale, and now 10^21 with zettascale. But the essence of the Zettascale Initiative being 1000x to me starts with the current performance per watt baseline. We'll disclose more into that in time, and I'm sure you'll ask questions on why and all that stuff.
But the current baseline, if you just think about it, what we are using to build Exascale and what others are using to build Exascale - the technology foundations for those were laid out more than 10 years ago. The questions of what process technology, or what packaging technology - those were in the works and in various forms of manufacturing for the last decade. So exascale is the culmination of a decade-plus long of work into a product.
IC: So in the same way, would that mean that when you say zettascale today essentially all of the work that would go into it is already happening now?
RK: It is already happening. In fact I think Pat (Pat Gelsinger, CEO Intel) said it quite well - the amount of time it took from each generation from Tera to Peta, from Peta to Exa, and the timeline we set from Exa to Zetta is actually shorter than the previous transitions. That is bold, that is ambitious, but we need to unleash the technology pipeline.
On the foundational physics, we do need different physics or more physics to solve the problem. So when you have those moonshot type of initiatives, both the technology industry and our in-house manufacturing process technology teams, all the scientists that work on it, and some of our partners in the equipment industry or in the IP industry and all - it's a call for action for all of them because of the demand exists today.
These are in AI workloads and our desire to simulate things. You know excellent work was done recently by our friends at the Fugaku supercomputer, using that facility, that capability to simulate the spread of COVID. That was impactful. Now, I wish we had those simulations done at the beginning of 2020, and that we had a better understanding earlier. There is no reason for us to be waiting for the next big event, whether it's a natural event or a calamity ahead of us. We start simulating them at Earth scale, at planet scale, and that's what computing is about.
In fact, in many ways, it’s one of the cheapest resources in the universe. If you think about it computing is actually, compared to many inventions or many other ways we spend electricity on, the delivered work per watt of computing is super energy efficient.
IC: But it’s not enough.
RK: It's not enough. Yes. Don’t worry, 1000x is just three zeros!
IC: It's interesting that you mentioned Fugaku, because the chip that they use is built primarily for 64-bit double-precision compute. But you also mentioned AI in there, which is a mix of quantization and reduced precision compute. Again, sorry to ask this question, and to bang on about it, but when we talk set Zettascale, we are talking one machine on double-precision compute, even with everything else involved, we are still talking double-precision?
RK: Yeah, yeah, absolutely. During the journey towards Zettascale, we expect us (and others) will take advantage of architectural innovations based on the workload - whether it is like a lower precision bit format, or some other interesting forms of compression. They'll all be a part of the journey. Nut to drive a set of mathematical initiatives, or kind of math-based initiatives on architecture, memory, interconnect, and process technology, we made it very simple. It's Zettascale, with 64-bit floating-point.
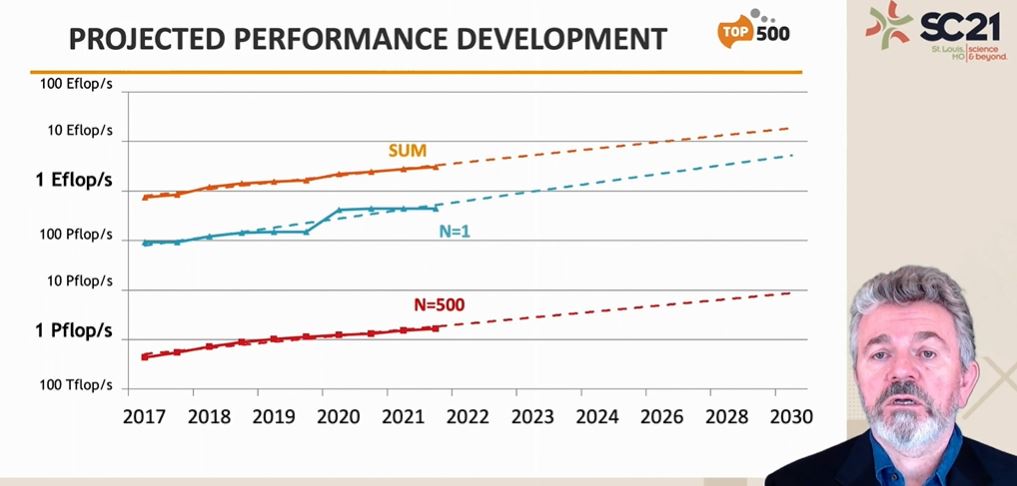
IC: You mentioned earlier that this is an acceleration of the industry progression, going from Tera to Peta, to Exa, and onto Zetta. If I just bring up the TOP500 supercomputer charts that they produce every six months, we're about to achieve ExaFLOP computers today. In that 2027 timeframe Intel is predicting for Zettascale, their graphs extrapolate out to only a 10 ExaFLOP system, not a 1000 ExaFLOP system. That's a bit of a jump, and naturally, a top supercomputer like that requires large investment - it requires a specific entity to build it, and contracts in place. Aurora's first contract was pre-2018, so how much needs to be in place very soon to hit that 1000x?
RK: Ian - one key thing to be able to do these kind of jumps is that the system architecture needs to change as well. So if you're taking the current system architecture on how supercomputers are built, taking what's in a node and asking how much efficiency I can get, the most ambitious numbers I can throw mean you land in that 10x range, maybe, or 20x-30x if you combine all the technologies. But if you take the whole system and ask where is the energy going at the whole ExaFLOP system level, you see a ton of opportunity beyond the current CPU and the GPU that's inside a single node. That's the system-level thinking that's very much part of our zettascale initiative – we’re looking at what the system-level architecture changes are that we need to do to be able to get to that interesting compute density, that interesting performance per watt increase. At an opportune time, we'll be laying out all those details - I won't go into all those details today, but suffice to say there is enough opportunity.

IC: Is this going to be Intel driven, or Intel and its partners designing new potentials? Or is it going to be customer-driven? There’s that famous quote that if you just ask customers, all they want is faster machines, not anything new – so if innovation has to happen at multiple levels, how are you going to provide something that both your customers want but is also a paradigm shift. If you go too far, they might not adopt it, as that's always a barrier in these things as well.
RK: There are phases to that, in the beauty of the supercomputing community, the HPC community. They are very eager first adopters of many things - they experiment, they lean in, sometimes just to get the bragging rights number to build those ‘Star Trek’ machines so are likely to be the first guinea pigs on a new technology. It’s a good thing that there is that community, and we are really passionate about that. That's my focus. Now, our goal is that we said that it's not just building a bragging rights Zettascale computer or something - we want to get this level of computing accessible to everyone. That is Intel’s DNA – that’s the democratization of it. In our thinking, every one of the technologies we pack into Zettascale is something that’s actually in our regular roadmap. It’s our mainstream roadmap in some shape or form, and that's how we're thinking about it.
IC: I wanted to go through some of the timescales for Zettaverse. You’ve already been through them with Patrick Kennedy from ServeTheHome – it’s annoying because I asked for this interview before you bumped into him at Supercomputing and had this chat! But to build on what was published there - in that interview, you said Zettascale had three phases. First is optimizing Exascale with Next-Gen Xeon and Next-Gen GPU in 2022/2023; the second phase is in 2024/2025 with the integration of Xeon plus Xe called Falcon as well as Silicon Photonics or ‘LightBringer’; then a third phase simply labeled Zettascale because it's 4 to 5 years away, and Intel doesn't talk about things that far out. It sounds to me like you're aligning these phases with specific products and introductions into the market?

RK: Definitely. With phase one and phase two, we have more clarity on the products. But phase three is about our technology roadmap. When I use the word technology, by the way, just for your audience and readers, it is things that take a long time. It means process technologies, or a new packaging technology, or the next generation of silicon photonics - those take a long time. The products align to things like Sapphire Rapids, like Alchemist or BattleMage, where we pack these technologies into a particular architect system architecture.
IC: You’ve spoken about this 1000x jump in performance, and with Patrick you labeled it as an architecture jump of 16x, power and thermals are 2x, data movement is 3x, and process is 5x. That is about 500x, on top of the two ExaFLOP Aurora system, gets to a ZettaFLOP.
Just going through some of the specific numbers - the 16x for architecture is the biggest contribution to that. Should we think of that in pure IPC improvements, or are we talking about a full spectrum of improvements combined with the paradigm shifts, such as processing and memory and that sort of thing?
RK: A combination of both I'd say. The foundational element is the IPC per watt improvement. We know how to do 16x performance improvement pretty easily, or relatively. But doing it without burning the power is the challenge there in terms of both the architecture and microarchitectural opportunities that are ahead of us.
IC: On the power and thermal side, you mentioned 2x, which is the lowest multiplier. You meant the ability to use both a lower voltage and better cooling, although I immediately heard it and thought we're going to start getting 800 to 1000 watt GPUs! But this sounds more around better power management, how to architect the power, and the ability to have the process for thermal packaging and voltages. That also moves into how architecture is done, as well as some of the others on this list, such as packaging and integration. Some of these multipliers overlap, significantly, so isn’t it hard to tell them apart in that way?
RK: Some of them have opportunities beyond those numbers. For example, when we say ‘power and thermals’, it's also power delivery - if you just look at the way we build computers today, just the regulated losses that you have on how we deliver current to the chip. With integration at a system scale, there are opportunities - not just Intel identified opportunities, but many folks outside Intel have called things out, such as driving higher voltages [in the backplane] to drive lower current in. So there are opportunities there. The data center folks have been taking advantage of some of this stuff already, as well as the big hyperscalers - but there is more available with integration.
But you said something very interesting - if we viewed Zettascale as a collection of components, such as GPUs, CPUs, and memories and all - each of them are fed separate power. You could have a 300 watt GPU and a 250 watt CPU. That's one way of doing the math. But if I have X amount of compute, what amount of current is needed to deliver to that compute - there are large power losses today because each component has its own separate power delivery mechanisms, so we waste a lot of energy.
The key idea behind all of this stuff is the ‘unit of compute’. Today, when I say ‘unit of compute’, we mean that a CPU is a unit of compute, or a single GPU is a unit of compute. There is no reason why they have to be that way. That's what we define today for market reasons, for product reasons and all that stuff, but what if your new ‘unit of compute’ is something different? Each unit of compute has a particular overhead - beyond the core compute, it’s about delivering power to a thermal solution. There’s cost too, right? There bunch of materials on the board and all the repetitive components could potentially be combined for lower overall losses.
Historically, this is one of the foundations of Moore's Law. Integration with Integration. We drove this extraordinary foundation, and now we have a supercomputer in your pocket in a phone. No reason that aspect of Moore's law needs to stop, because there's still an opportunity just even beyond transistors. Just the integration - integration can drive some order of magnitude efficiencies.

IC: One goal of this interview was to talk about the ‘metaverse’ buzzword along with ‘zettascale’, and one topic that straddles the two is One API. We just had the launch of OneAPI 1.0 Gold, and part of the Zettascale initiative means we're looking at 2.0 and 3.0 over the next few years. So far, what's the pickup been like on OneAPI? What has been the response, the feedback? Also, beyond that, for future generations is it all just going to be about specific hardware optimizations, smart compilers, customer libraries - can you sort of go into a little bit of detail there?
RK: The pickup so far has been really good. I think soon we'll be sharing some numbers on the installed user base and all that. But the key thing I'm looking forward to, and I think we are all looking forward to, is when our GPU hardware starts becoming available through this year. We expect that knee in the curve in OneAPI adoption to happen. There will be more excitement! Developers have been using OneAPI, but they want to test it on our new hardware. I think that will bring excitement, and we will see that momentum coming later this year.
So beyond the current features of the first phase of OneAPI, there are two aspects. First is leveraging our x86 library base for our upcoming GPUs and other hardware. The second is the data-parallel nature, SIMT abstraction that is popularized by CUDA, OpenCL, and such. A clean interface, a clean programming model, that's available to all, supporting everybody’s hardware. Combining that with all Intel's tools is a really big investment. That's Phase One.
Phase Two, particularly with the architectures that I already hinted at coming, will unlock new forms of parallelism, making it much easier for compute and memory management. It will make it much easier for people to write workloads that deal with petabytes of data, as an example. All those features will come in the next flavors of OneAPI 2.0 and 3.0 as the hardware evolves to make it all easy.
IC: So going full-on Metaverse. Metaverse and Zettascale, in my mind, occupy a very similar space it’s all about compute. Aside from a few mentions from Intel, particularly a talk from you at the RealTime Conference in December, Intel hasn't said too much about it. Personally I think Intel hasn’t said much as it's still a lot of search engine buzzwords, and not a lot of substance. But at the high level, as a hardware vendor, when does Intel move from the sidelines to dipping their toe in the water?
RK: I hesitated using the word Metaverse, and other buzzwords. Even back in 2018, when I came here to Intel, I said the thing that I was passionate about (and what kind of got me to Intel) is this enabling of fully immersive virtual worlds that are accessible to everyone. The amount of compute needed is as I said back then, literally PetaFLOPs of compute, Petabytes of storage, at less than 10 milliseconds away from every human on the planet. That is the vision mission that we are on, that Intel is still on.
If you actually think about it, what is a Zettascale computer? Or what's an Exascale computer? It is one cluster of machines that you can schedule a piece of work on. If I have some work to be done, and I have access to X amount of machines, but if I can submit one job and spread it across all these machines, it can get done fast. As the network latencies improve, you end up surrounded by a petaflop machine within every 10-mile radius. The 10-mile radius is limited by the speed of light for latencies, but that is what the computational fabric required enables.
But what is my vision of the Metaverse? There are different forms of the Metaverse, from the toy cartoony stuff and up, there will be lots of interesting versions of it, and they'll all be useful. I'm looking forward to it, but the kind of photo-real immersive stuff that I can get myself in. For example, this conversation that you and I are having over the internet, where we don't feel like we're in the same room – imagine having a proper three-dimensional interaction here. That is the Metaverse that I am looking forward to, where it erases distances, it erases geographical boundaries, and literally puts us both in the same room. It means I’m interacting with the best version of you, and you are interacting with the best version of me. That is the Metaverse which I look forward to.
So for Intel, we will be progressively saying more things about our take on it. Like I said, at the RealTime conference, the way we are looking at it there are three layers.
First is the compute infrastructure layer, which is fundamentally what our hardware roadmap silicon roadmaps in improving on. The second is the infrastructure layer, and we have been at work on creating interesting hardware and software there. I'll be saying more about that in a couple of weeks. We showed some demonstrations of what we've been working on at the conference. Then the last layer is what I call the intelligence layer, which is leveraging all the new AI techniques. We want to package them all up so that you effectively deliver more compute (or a better visual experience) to a low-power device more productively.
So that's kind of the way we're thinking about Metaverse. You'll see us say and talk more about it, whether we lean into the term Metaverse, or Web3, or some other buzzword. I’ll leave it to others for the buzzwords, but we are working away.
IC: ‘Metaverse’ feels like a continuation of virtual reality, with just added layers and complexity. The adoption of virtual reality hasn't been universal, and ‘the Metaverse’ feels like it might become a subset of VR. Is there really value in those VR-like outcomes?
RK: Even if I remove VR, just for a second, for the last two years we've all been stuck in front of some display, or multiple displays, right? Even without wearing a headset, I think a more immersive collaboration environment would have been beneficial. Before we started recording, you were complaining about some Zoom feature that you wanted – in my mind I'm talking about 1000x to those Zoom features. I'm of the mind that we will be surrounded by billions of pixels, in one shape or form. I remember a decade ago, we had a debate at Apple about whether to continue building 27-inch panels, because everybody is on their smartphone. But we can leverage those pixels to provide a much more productive experience than we are doing today. That is my foundational thing for Metaverse - whether for those pixels you wear them on your headset in VR, or they’re in front of you, I think it will be one of the tools that we have.
Many thanks to Raja and his team for their time.
Many thanks to Gavin for his transcription.








45 Comments
View All Comments
prophet001 - Wednesday, March 9, 2022 - link
Miss me with that metaverse.Hifihedgehog - Friday, March 11, 2022 - link
All I read here is just constant bellowing of buzzword advertising fluff. I honestly found Ian's questions significantly more enlightening and informative than this conman's half-hearted responses. I will be so happy when this guy leaves Intel. Raja Koduri is the living embodiment of a corporate parasite. Once a person gets into high-level executiveship, it is a life pass to be a leech regardless of results. He will do terribly here just like he did at AMD, mark my words. I have little confidence in Arc succeeding and now that the GPU fever is cooling off right as it is set to release, it will depend totally on merit and not blind and insatiable demand.prophet001 - Friday, March 11, 2022 - link
Well you're not wrong lol.mode_13h - Monday, March 21, 2022 - link
I thought the interview was worthwhile, in terms of what Ian was able to pin down.> Raja Koduri is the living embodiment of a corporate parasite.
Have you ever heard of the Peter Principle? I'm not saying that's what happened, but it could be. Or, another phenomenon is that sometimes the easiest way to get rid of someone incompetent at their job is to promote them.
> I have little confidence in Arc succeeding
Intel has enough hard-working, competent engineers that I think it'll do alright. I think it's got good potential for GPU compute, so that's my main interest.
ElGus - Wednesday, March 9, 2022 - link
Sorry for my bad English.But reading all the interviews makes me feel like watching an infomercial.
I'm always waiting for more detail or precision.
Like the magazines that you found when you go to a doctor and wait.
Not sure how to say it in other words.
whatthe123 - Wednesday, March 9, 2022 - link
other than leaking company design secrets, hes pretty much laid out what they believe they can do. their goal is to have a complete interconnected platform that cuts down on power delivery losses. add that in with general architecture and node improvements to reach zetaflop performance at the supercomputer level.Since they've qualified that it is zeta FP64 performance, I honestly don't believe intel will reach it by 2027. If it was some other metric like mixed FP then yes, but pure FP64 up to zeta in 5 years? ehhh good luck with that
JayNor - Wednesday, March 9, 2022 - link
The part about the oneAPI software advances coming is more interesting to me. Maybe they're learning something from the supercomputer users. It's good to see them listening.mode_13h - Monday, March 21, 2022 - link
I just hope they don't follow AMD's example and simply make a 1:1 CUDA clone.Calin - Thursday, March 10, 2022 - link
There's also a lot to be gained from lowering the energy to "move bits around" i.e. interconnects. A larger supercomputer that is not a "billion independent nodes" or "Chinese lottery" style might consume as much power in moving data around as in processing it.JayNor - Thursday, March 10, 2022 - link
Yeah, moving data from the chip package to the front panel requires big heat sinks and retimers if done over copper. This was presented when intel did their 12.8Tb switch with co-packaged optics demo in 2020. I believe we'll see the 25.6Tb switch demo this year, based on some slides from Robert BlumeThe UCIE announcements mentioned its use for hooking up to optical transceivers. Raja's servethehome interview mentions "lightbender" for the Falcon Shores chip